'Deepfake' detektori pali na testu
Nijedan od 16 vodećih detektora ne može pouzdano identificirati lažne uratke u stvarnom svijetu, otkrili su australski i korejski istraživači


Nedavno objavljeni rad na portalu arXiv koji su zajednički izradili australska nacionalna znanstvena agencija CSIRO i južnokorejsko Sveučilište Sungkyunkwan otkrio je ozbiljne ranjivosti u postojećim deepfake detektorima. Istraživanje je procijenilo 16 vodećih detektora i pokazalo da niti jedan od njih nije u stanju pouzdano identificirati deepfake u stvarnim uvjetima.
Metodologija Istraživanja
Istraživači su razvili okvir u pet koraka za procjenu alata koji uključuje tip deepfakea, metodu detekcije, pripremu podataka, obuku modela i validaciju. Pritom su identificirali i 18 faktora koji utječu na točnost detektora koji su testirani u različitim scenarijima, uključujući crnu, bijelu i sivu kutiju.
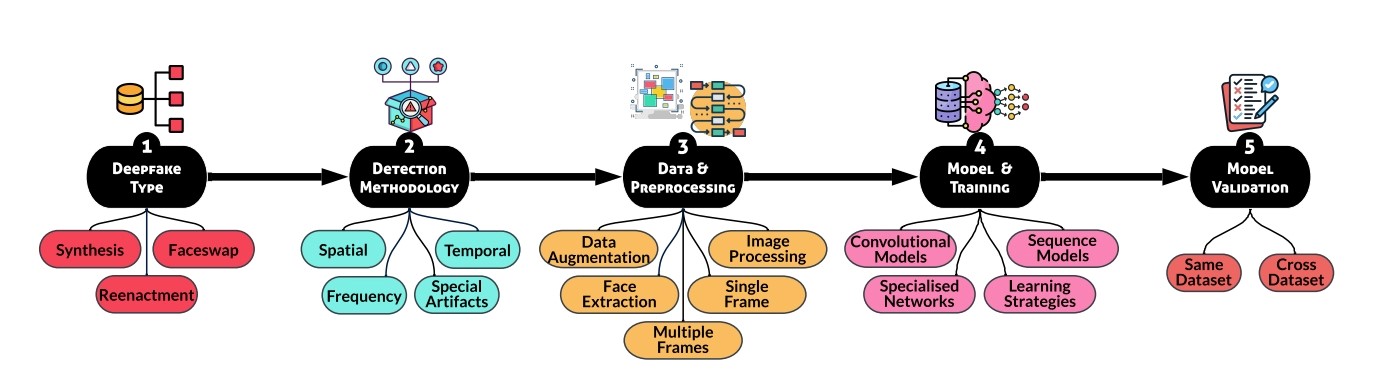
Postojeći detektori pokazuju ozbiljne slabosti, posebno kada se suočavaju s radovima koji se ne nalaze u njihovim treniranim podacima, zapažaju istraživači. Na primjer ICT (Identity Consistent Transformer), detektor obučen na licima poznatih osoba, nije bio učinkovit u detekciji deepfakea s nepoznatim osobama. Detektori su pali na ispitu, svejedno bila riječ o synthesis deepfakes koji generiraju potpuno nova sintetička lica, faceswap deepfakes radovima u kojima se lice jedne osobe zamjenjuje drugim ili reeanactment deepfakes u kojima se zadržavaju crte lica neke osobe, ali se mijenjaju njeni izrazi.
Integracija podataka
Istraživači pozivaju na hitna poboljšanja, predlažu razvoj više detektora i korištenje različitih izvora podataka kako bi se poboljšala točnost detekcije. Naglašavaju i potrebu integracije audio, tekstualnih i meta podataka u modele za detekciju, kao i primjenu strategija poput fingerprintinga, odnosno ugradnje umjetnih i GAN otisaka u slike i video zapise kako bi se bolje pratilo podrijetlo deepfakea.

Prva metoda uključuje ugradnju jedinstvenih oznaka u trening podatke generativnih modela koji se prepoznaju u generiranim deepfake radovima, a druga na prirodne oznake koje generativni modeli ostavljaju u generiranim sadržajima.


























