LM Arena namješta rezultate AI testova?
Meta je testirala 27 verzija Llama-4 prije objave, te Google s 10 verzija Gemini i Gemma modela iz kojih su za prikaz odabrali samo one najbolje ocijenjene

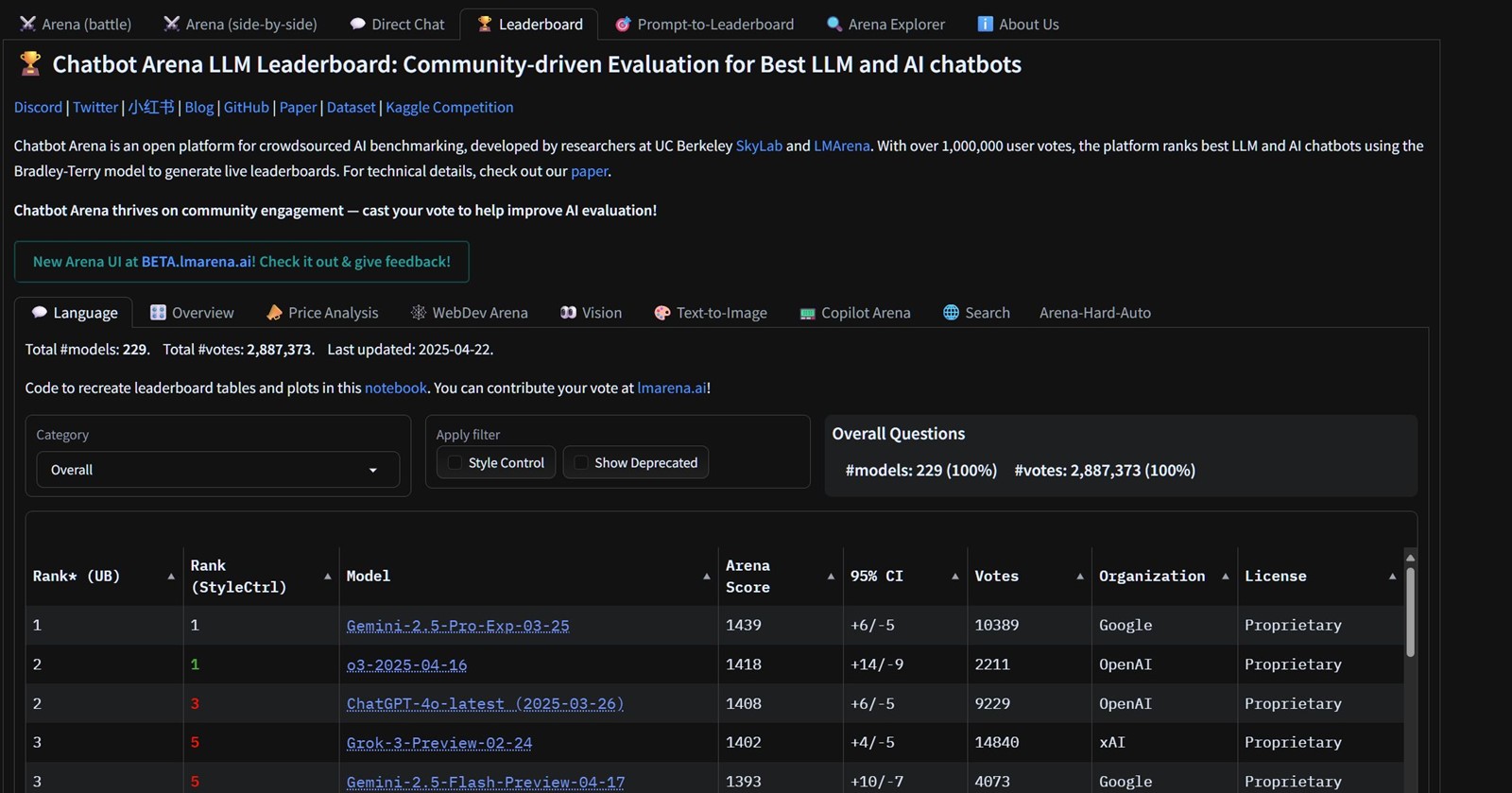
Nova studija istraživača s Cohere Labs, Princetona i MIT-a optužuje popularnu platformu za rangiranje AI modela, LM Arenu, za pristranost prema zatvorenim (proprietary) modelima. LM Arena, pokrenuta 2023. kao istraživački projekt na UC Berkeley, rangira AI modele temeljem korisničkih glasova o kvaliteti odgovora ("vibe test"). Studija, objavljena na arXivu, tvrdi da je rangiranje tako namješteno da favorizira velike tvrtke.
Prvo, LM Arena dopušta developerima zatvorenih modela testiranje više privatnih verzija, dok se javno prikazuje samo ona s najboljim performansama. Kao primjer navodi se Meta koja je testirala 27 verzija Llama-4 prije objave, te Google s 10 testiranih verzija Gemini i Gemma modela.
Drugo, studija ukazuje na nerazmjernu zastupljenost zatvorenih modela poput Geminija, ChatGPT-a i Claudea u usporedbama unutar Chatbot Arene. Google i OpenAI zajedno čine preko 34% prikupljenih podataka o interakcijama, dajući tim tvrtkama više podataka za evaluaciju u usporedbi s developerima otvorenih modela.
Autori studije predlažu ograničavanje broja privatnih testiranja po grupi, objavu svih rezultata (i nefinalnih) te pravednije uzorkovanje modela u Areni kako bi se osigurala ravnopravnost otvorenih modela.
LM Arena je nedavno postala korporativni entitet, a njezina rang lista postaje sve utjecajnija (Google ju je citirao pri lansiranju Gemini 2.5 Pro).



























